|
|
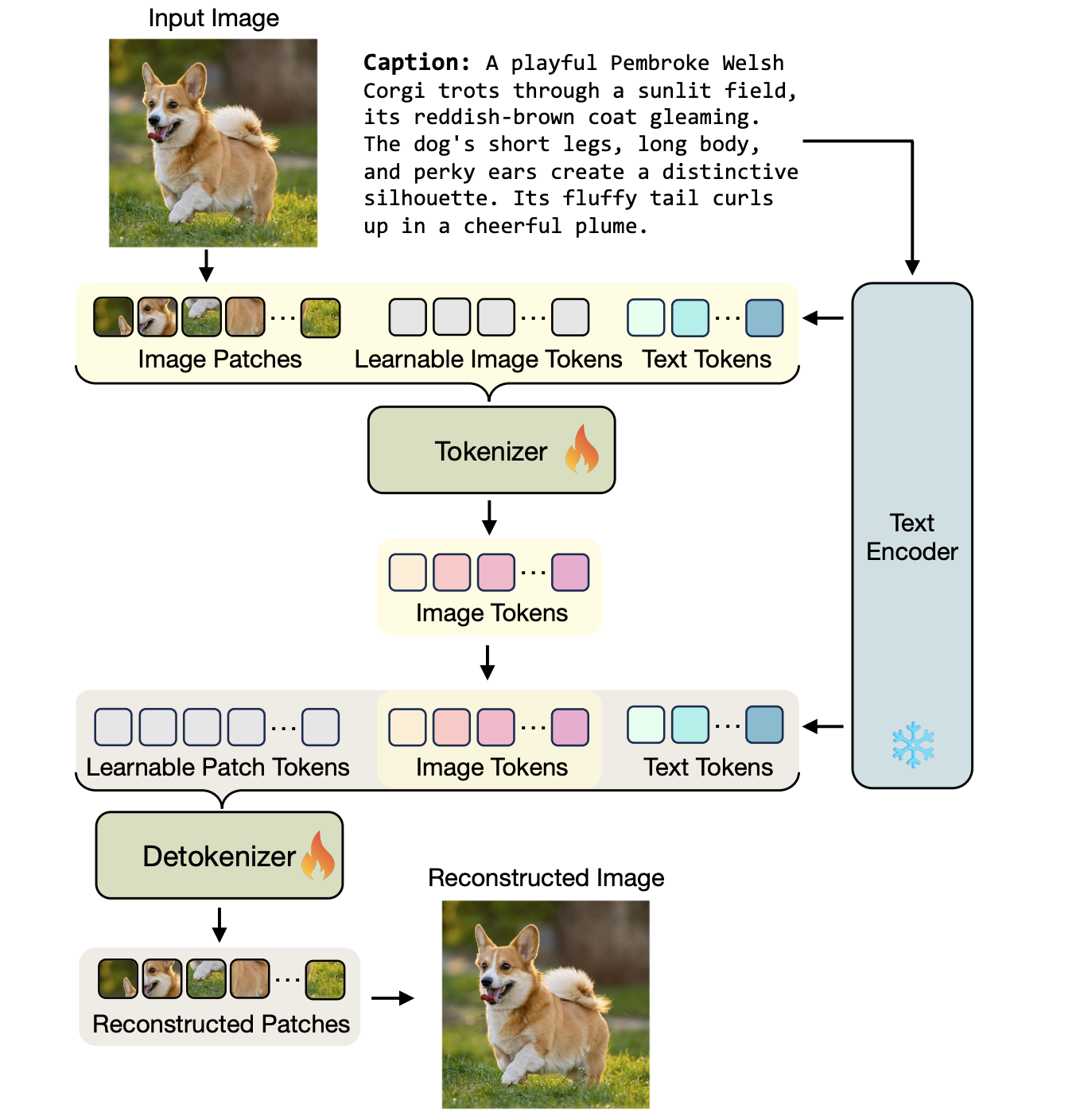
Kaiwen Zha, Lijun Yu, Alireza Fathi, David Ross, Cordelia Schmid, Dina Katabi, Xiuye Gu.
Language-Guided Image Tokenization for Generation (TexTok).
CVPR 2025.
[paper]
|
|
|
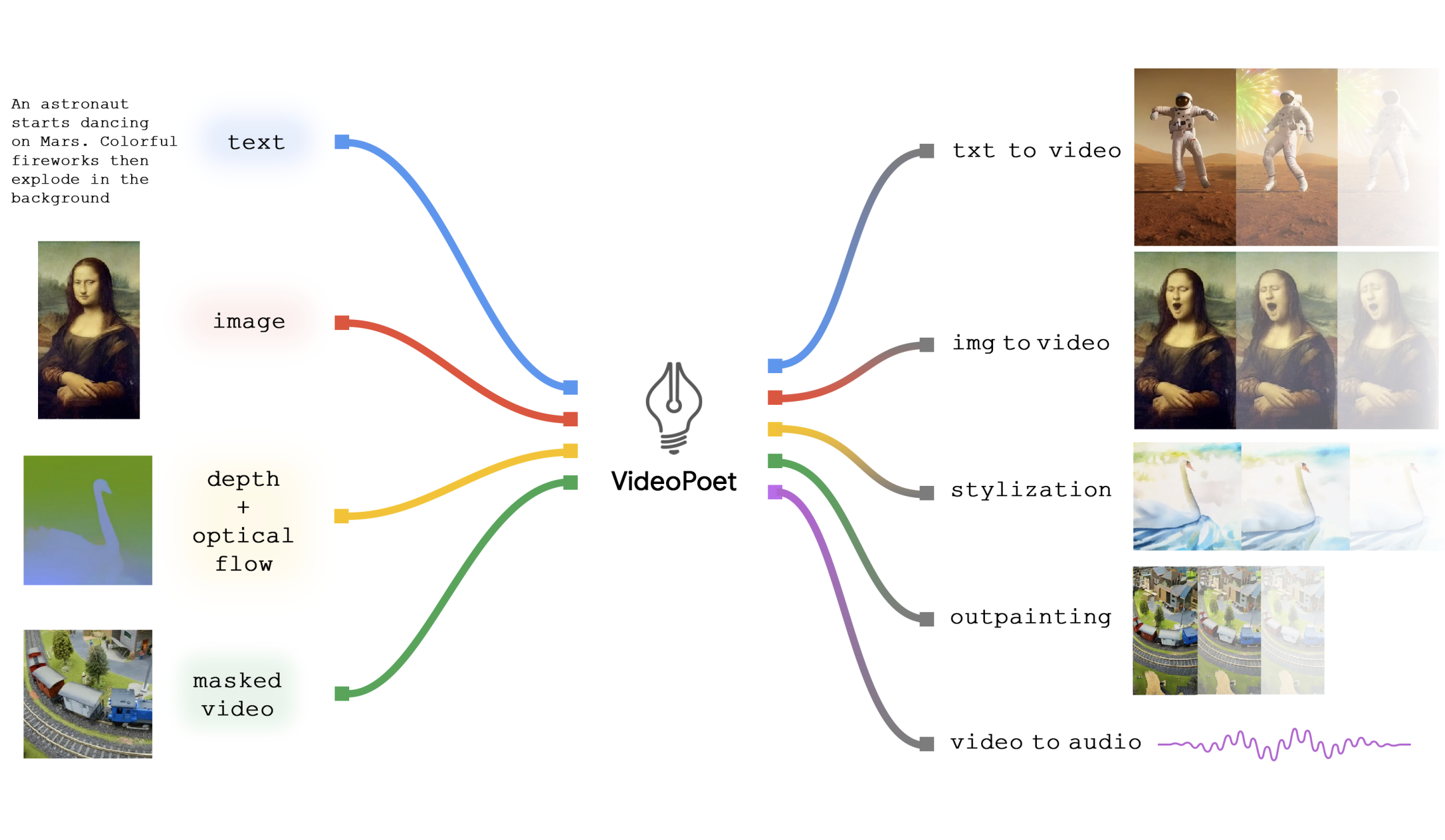
Dan Kondratyuk*, Lijun Yu*, Xiuye Gu*, José Lezama*, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, Yong Cheng, Ming-Chang Chiu, Josh Dillon, Irfan Essa, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David Minnen, David Ross, Grant Schindler, Mikhail Sirotenko, Kihyuk Sohn, Krishna Somandepalli, Huisheng Wang, Jimmy Yan, Ming-Hsuan Yang, Xuan Yang, Bryan Seybold, Lu Jiang.
VideoPoet: A large language model for zero-shot video generation.
ICML 2024, Best Paper Award, Patent.
[paper]
[website with demos]
[blog]
|
|
|
Jiarui Xu, Xingyi Zhou, Shen Yan, Xiuye Gu, Anurag Arnab, Chen Sun, Xiaolong Wang, Cordelia Schmid.
Pixel-Aligned Language Model.
CVPR 2024.
[paper]
[code]
|
|
|
Shuyang Sun, Runjia Li, Philip Torr, Xiuye Gu*, Siyang Li*.
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor.
CVPR 2024.
[paper]
[code]
[website]
|
|
|
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Li Fei-Fei, Irfan Essa, Lu Jiang, José Lezama.
Photorealistic video generation with diffusion models (W.A.L.T).
ECCV 2024.
[paper]
[website]
[video demo]
[more samples]
|
|
|
Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A Ross, Lu Jiang.
Language Model Beats Diffusion--Tokenizer is Key to Visual Generation.
ICLR 2024.
[paper]
[website]
|
|
|
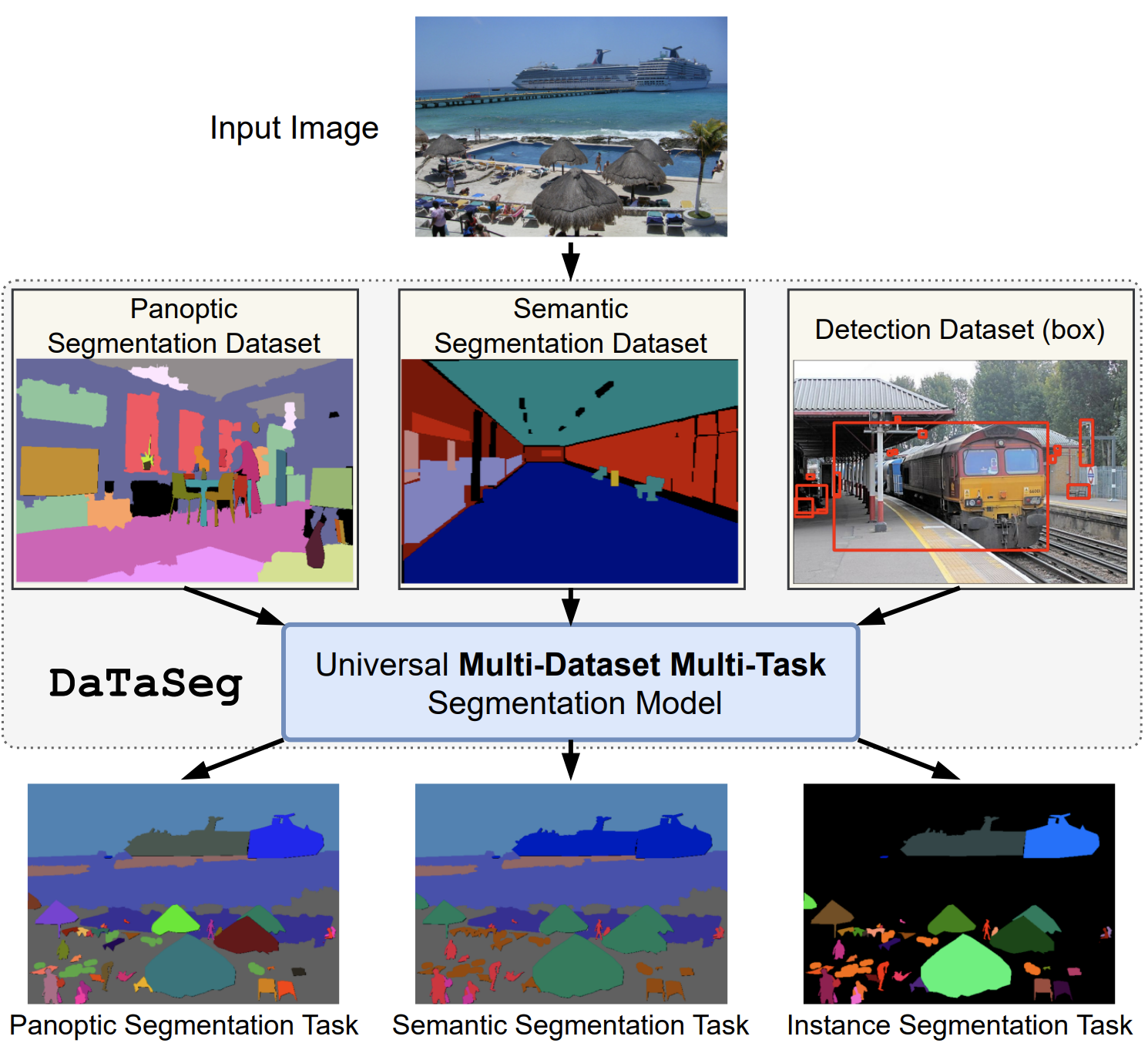
Xiuye Gu, Yin Cui, Jonathan Huang, Abdullah Rashwan, Xuan Yang, Xingyi Zhou, Golnaz Ghiasi, Weicheng Kuo, Huizhong Chen, Liang-Chieh Chen, David A Ross.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model.
NeurIPS 2023.
[paper]
[Objects365 instance segmentation dataset]
[poster]
|
|
|
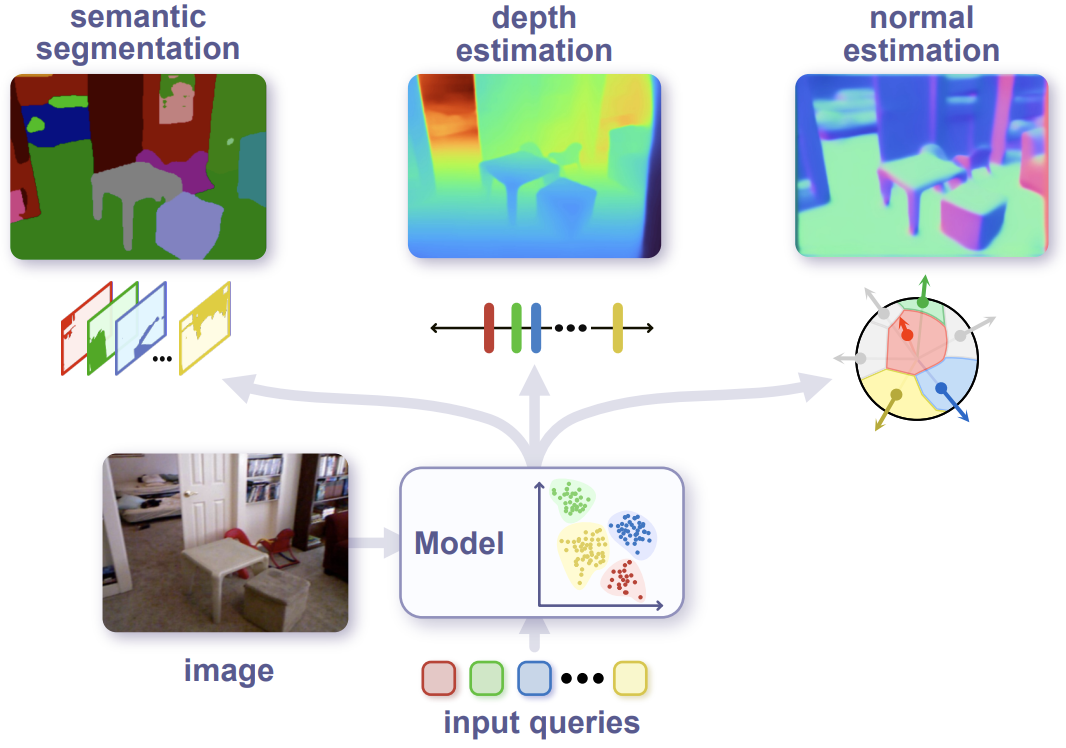
Xuan Yang, Liangzhe Yuan, Kimberly Wilber, Astuti Sharma, Xiuye Gu, Siyuan Qiao, Stephanie Debats, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Liang-Chieh Chen.
PolyMaX: General Dense Prediction with Mask Transformer.
WACV 2024.
[paper]
[supp]
|
|
|
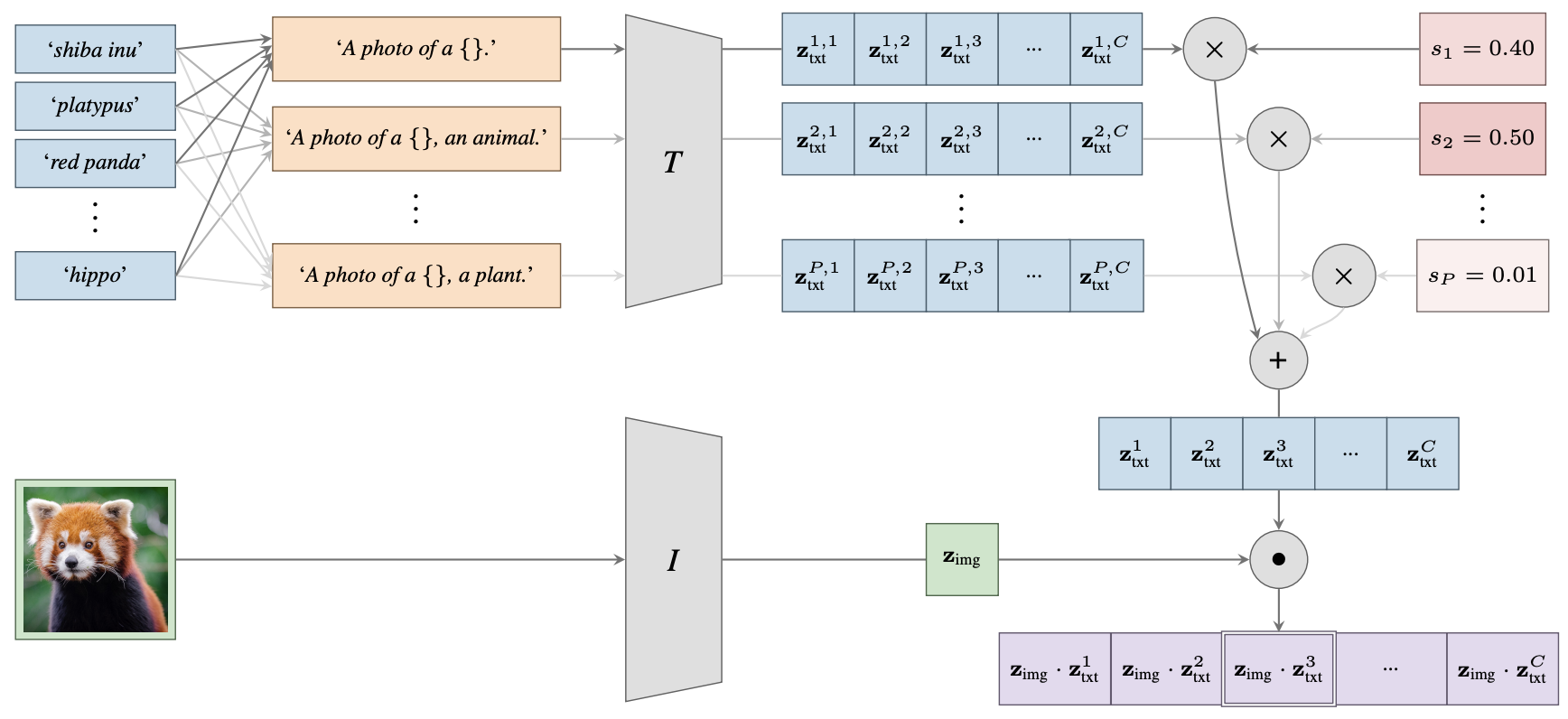
James Urquhart Allingham, Jie Ren, Michael W Dusenberry, Jeremiah Zhe Liu, Xiuye Gu, Yin Cui, Dustin Tran, Balaji Lakshminarayanan.
A Simple Zero-shot Prompt Weighting Technique to Improve Prompt Ensembling in Text-Image Models.
ICML 2023, Patent.
[paper]
|
|
|
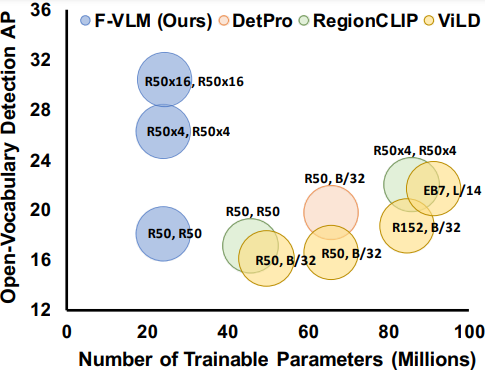
Weicheng Kuo, Yin Cui, Xiuye Gu, AJ Piergiovanni, Anelia Angelova.
F-vlm: Open-vocabulary object detection upon frozen vision and language models.
ICLR 2023, Patent.
[paper]
[code]
[website]
[blog]
|
|
|
Golnaz Ghiasi, Xiuye Gu, Yin Cui, Tsung-Yi Lin.
Scaling open-vocabulary image segmentation with image-level labels (OpenSeg).
ECCV 2022.
[paper]
[code]
[colab demo]
[poster]
|
|
|
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, Yin Cui.
Open-vocabulary object detection via vision and language knowledge distillation (ViLD).
ICLR 2022.
[paper]
[code]
[colab demo]
|
|
|
Xiuye Gu, Weixin Luo, Michael S. Ryoo, Yong Jae Lee.
Password-conditioned Anonymization and Deanonymization with Face Identity Transformers.
ECCV 2020.
[paper]
[code]
[demo video]
[1-min presentation]
[10-min presentation]
|
|
|
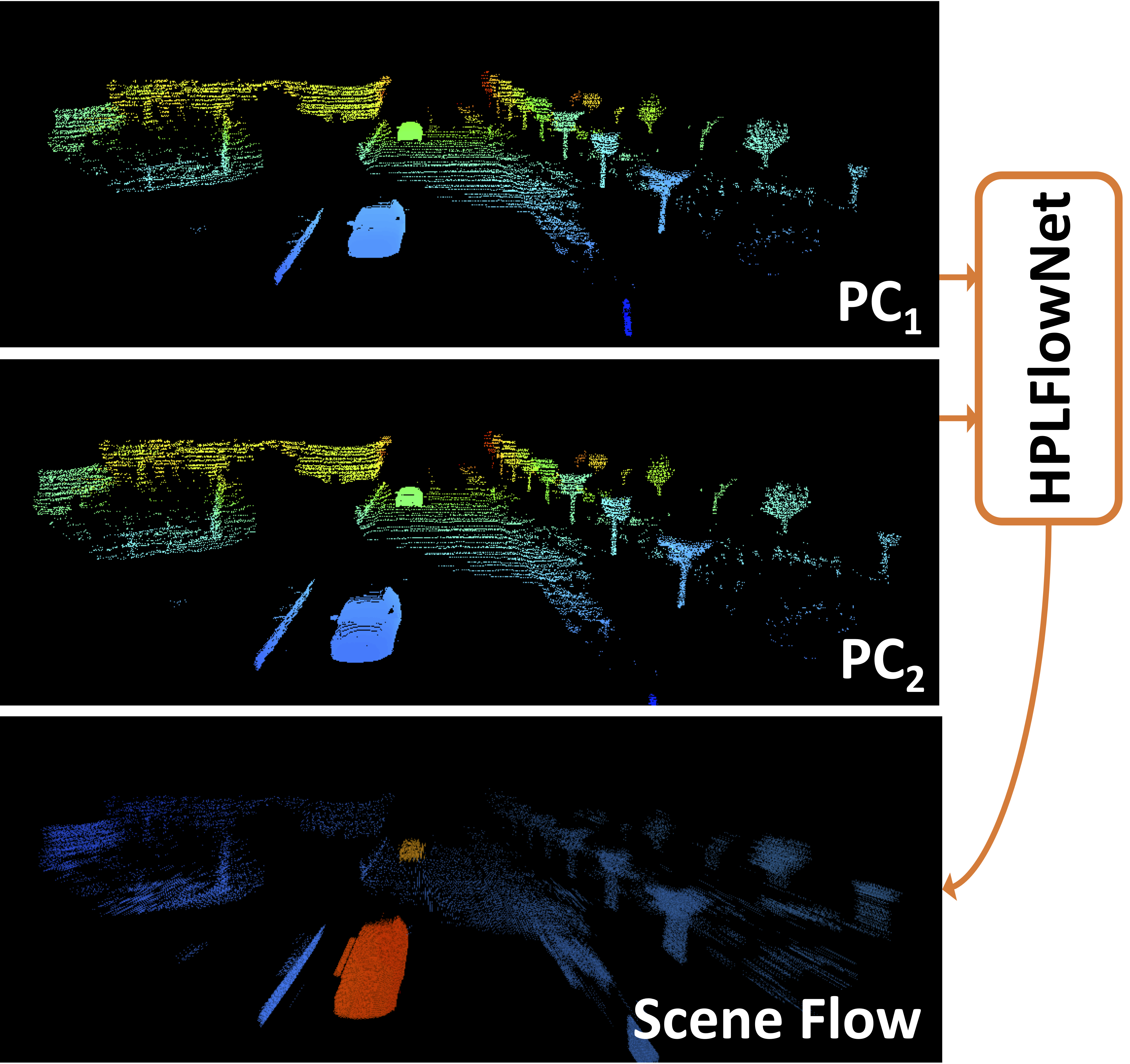
Xiuye Gu, Yijie Wang, Chongruo Wu, Panqu Wang, Yong Jae Lee.
HPLFlowNet: Hierarchical Permutohedral Lattice FlowNet for Scene Flow Estimation on Large-scale Point Clouds.
CVPR 2019.
[paper]
[supp]
[code]
[poster]
[video]
|
|
|
Maheen Rashid, Xiuye Gu, Yong Jae Lee.
Interspecies Knowledge Transfer for Facial Keypoint Detection.
CVPR 2017.
[paper]
[code]
[anotation tool]
|